| N-T.ru / Текущие публикации / История науки |
Долгое прощание с лысенковщинойВ.П. ЛЕОНОВ Часть 4Самозарождение «Р <»
|
| Описание из диссертации №1 [стр. 41] | Описание из диссертации №2 [cтр. 53] | Описание из монографии [102] [стр. 48] | Описание из диссертации №3 [стр. 40] |
| Достоверность различия сравниваемых величин определяли с помощью показателя точности Р по таблице Стьюдента, где он располагается в зависимости от значений t и n. | Достоверность определяли с помощью абсолютного показателя точности «р», который находили по специальной таблице, где он расположен в зависимости от (t) Стьюдента и числа степеней свободы «n?». | Достоверность различий средних арифметических определяли по абсолютному показателю точности процентных точек распределения Стьюдента в зависимости от коэффициента достоверности (t) и числа степеней свободы (n). | Достоверность различных средних арифметических определяли по абсолютному показателю точности (P) по таблице процентных точек распределения Стьюдента в зависимости от коэффициента достоверности (t) и числа степеней свободы (n). |
Как видим, эти четыре описания весьма похожи друг на друга. Менее всего отличаются между собой описания из диссертаций №2, 3 и монографии [102]. Наши исследования показали, что данный мем имеет достаточно большой «возраст». К примеру, если кандидатские диссертации №1 и №3 защищены в 1995 г. и 1997 г., а коллективная монография [102] издана в 1996 г., то диссертация 2 датирована еще 1969 г. Однако ни в одной из этих работ нет одного и того же исследователя, более одного раза выступающего в роли автора, либо в роли научного руководителя. Это делает более вероятным предположение о том, что «инфицирование» этим мемом произошло от некого пятого источника, носителя данного мема. Хотя не исключено, что некоторые из авторов упомянутых работ познакомились с ним и через предшествующие работы. Обратим также внимание читателей на наличие в 4-х случаях субмема «показатель точности», причем в 3-х случаях он называется «абсолютным показателем точности». Наши попытки найти наиболее вероятный источник инфицирования этим мемом успеха не имели. Попытаемся выяснить, какой смысл могли вкладывать авторы этих работ в «показатель точности», используя для этой цели следующий мем, использованный в монографии [102] и диссертации №3 и приведенный в таблице ниже.
Таблица 2.
| Описание из монографии [102] | Описание из диссертации №3 |
| На основании критерия t по таблице Стьюдента определялась вероятность различия. Различие считалось достоверным при p < 0,05, т.е. в тех случаях, когда вероятность различия составляла больше 95%.[стр. 48] | На основании t по таблице Стьюдента определялась вероятность различия (р). Различие считалось достоверным при p < 0,05, т.е. в тех случаях, когда вероятность различия составляла больше 95%. [стр. 40] |
Авторы монографии [102] не приводят в этом меме объяснения величины (р). В этом случае можно считать, что авторы подразумевают под величиной (р) уровень значимости, и тогда в последнем предложении использованного мема нет противоречия. Действительно, «при p < 0,05» мы имеем доверительную вероятность более 95%. Таким образом, вероятнее всего авторы монографии [102] подразумевали уровень значимости, величина которого дополняет доверительную вероятность до единицы: р = 1 – Рдов. Совершенно иную, противоречивую и бессмысленную конструкцию имеет этот мем в диссертации №3, где величина (р) определяется как «вероятность различия». В одном и том же предложении диссертант утверждает, что «Различие считалось достоверным при p < 0,05, т.е. в тех случаях, когда вероятность различия составляла больше 95%». Таким образом, мы имеем случай рекомбинации мемов, в результате которой новый мутантный мем приобрел достаточно искаженную и лишенную смысла форму.
Если рассмотренные выше 4 источника относятся к разным областям медицинской науки, то следующие 2 диссертации – №4 и №5, объединяет не только одна научная специальность 14.00.37 – анестезиология и реаниматология, но и один научный руководитель.
№4 – Патогенетическое обоснование вариантов экстракорпоральной детоксикации в комплексной терапии токсической стадии острого разлитого перитонита (экспериментально-клиническое исследование). Канд. дисс., 14.00.37 – анестезиология и реаниматология, 1996 г.
№5 – Экспериментальная оценка нового метода мембранного плазмафереза. Канд. дисс., 14.00.37 – анестезиология и реаниматология, 1998 г.
№6 – Оптимизация лечения осложненных острых воспалительных заболеваний придатков матки у юных женщин). Канд. дисс., 14.00.01 – акушерство и гинекология, 1997 г.
На первый взгляд различие же между этими мемами лишь в двух словах и одной букве.
Таблица 3.
| Описание из диссертации №4 [стр. 59] | Описание из диссертации №5 [стр. 21] | Описание из диссертации №6 [стр. 38] |
| Статистическая обработка результатов проводилась методом вариационной статистики с использованием «t»-критерия Стьюдента в условиях доверительной вероятности, равной 95% | Статистическая обработка результатов проведена методами вариационной статистики с использованием «Т»-критерия Стьюдента в условиях доверительной вероятности, равной 95% | Статистическая обработка полученных данных проводилась методом вариационной статистики с использованием «t»-критерия Стьюдента в условиях заданной доверительной вероятности, равной 95% |
Однако главное различие между ними в том, что авторы диссертаций №4 и №6 удовлетворились в своей работе только одним «методом» вариационной статистики, тогда как в диссертации №5 использованы уже несколько «методов». Иными словами, первые два диссертанта полагают что «вариационная статистика» и представляет собой один единственный метод, отождествляя его с t-критерием Стьюдента. Третий же диссертант предполагает наличие нескольких методов, которые и необходимы для использования Т-критерия Стьюдента. Как видим, эти две позиции имеют принципиальную разницу между собой. Вместе с тем, данные диссертации объединяет и субмем «в условиях доверительной вероятности», который достаточно верно выражает этот аспект описываемой процедуры.
Анализ публикаций показал, что достаточно широко используются оба типа мема, как тот, где постулируется наличие нескольких «методов», так и мем с наличием одного «метода». Отметим, что такое восприятие статистики авторами публикаций характерно не только для «вариационной статистики», но и для других видов статистики. «Статистическую обработку цифрового материала проводили по стандартному методу вариационной статистики на электронно-вычислительной машине ЕС-1033 ...» – стр. 58 диссертации «Состояние легочной вентиляции и механики дыхания при острой пневмонии», 14.00.05 – внутренние болезни, 14.00.43 – пульмонология, 1990 г. «В эксперименте различие показателей по сравнению с контролем и между возрастными группами оценивались методами вариационной и разностной статистики по критерию Стьюдента и считались достоверными при Р < 0,05» – стр. 46 диссертации «Функции почек и водно-солевой баланс у крыс при гипо- и гиперосмии в динамике беременности», 14.00.17 – нормальная физиология, 1992 г. «Вычисление, обработку полученных результатов осуществляли методом математической статистики при помощи программируемого микрокалькулятора «Электроника МК-52» с использованием специальных программ» – стр. 43 диссертации «Регионарная вентиляция, кровоток, механизмы дыхания у здоровых людей, больных хроническим бронхитом и бронхиальной астмой», 14.00.05 – внутренние болезни, 14.00.16 – пат. физиология, 1994 г. Интересно, как бы воспринял хирург следующее описание: «Внутриполостная операция производилась методом хирургии»?
Анализ мемов со сложной конструкцией не всегда позволяет достаточно надежно представить те понятия и их смысл, которые авторы пытаются описать с помощью рекомбинантных мемов. По своему языку и стилю такие описания нередко напоминают известные произведения А. Платонова «Котлован» и «Чевенгур». Приведем одно из подобных описаний содержащихся на стр. 30 диссертации «Клиника и дифференциальная диагностика инфекционых экзантем у детей», 14.00.09 – педиатрия, 14.00.10 – инфекционные болезни, 1998 г. и сделаем попытку его анализа. «Для определения значимости выборочных показателей, оценки сущности двух или нескольких показателей, а также определения связи между явлениями, полученных (так в тексте, выделено нами – В.Л.) в результате выборочных иследований, были использованы следующие формулы: «...(далее идут формулы ошибки среднего, среднеквадратичного отклонения и t-критерия Стьюдента – В.Л.). Итак, каков же смысл первого утверждения – «определение значимости выборочных показателей»? Предположим, что из выборки в 50 наблюдений мы получили выборочный показатель – среднее арифметическое значение систолического давления равное 90 мм рт ст. Что в таком случае мы должны понимать, согласно автору, под «значимостью выборочного показателя»? Как предлагает автор «оценить сущность двух или нескольких показателей», например того же среднего систолического и диастолического давления, содержания иммуноглобулинов, СОЭ и т.д. и какой смысл вкладывает автор в термин «сущность»? Не ясно и то, как собирается автор «определять связи между явлениями», поскольку ни в приводимых ниже формулах, ни в тексте диссертации об этом ничего не сказано. Продолжим авторский текст: «Пределы возможных колебаний (доверительные интервалы) средних величин, полученные в выборочном исследовании принимались равными удвоенной средней ошибке (+ 2m), что дает основание с вероятностью 95% отнести полученную закономерность ко всей генеральной совокупности». Итак, в первой половине этого предложения автор пытается объяснить технологию построения им 95%-ных доверительных интервалов. Однако из его объяснения не ясно, какой смысл имеет величина (+ 2m). Является ли это величина шириной 95%-ного доверительного интервала, либо же это полуширина, и тогда полная ширина доверительного интервала равна 4m? Остановимся на первой версии, согласно которой весь доверительный интервал равен 2m. В этом случае, принимая что данный интервал является симметричным (на это указывает нам используемый автором критерий Стьюдента, а стало быть распределение вероятностей подчиняется нормальному закону), получим, что левая граница интервала будет равна (Хср. = –1m), а правая граница интервала будет равна (Хср. = + 1m). Тогда полуширина доверительного интервала будет равна 1m. Но тогда для построения 95%-ного двустороннего доверительного интервала необходимо использовать квантиль уровня 0,975, который не может быть равен 1 даже для таких объемов выборок, которые равны нескольким сотням и тысячам. Так для бесконечно большого объема выборки он равен 1, 96, для выборки объемом 60 наблюдений соответствующий t-квантиль распределения Стьюдента будет равен 2. Но в этом случае вся ширина для 95%-ного доверительного интервала будет равна учетверненному значению m, а не удвоенному. Итак, какой же доверительный интервал строит диссертант и для каких обхемов выборок? Не меньше вопросов возникает и при изучении второй половины данного предложения, в которой речь идет о «полученной закономерности», поскольку ранее нигде автор ничего не говорит ни о видах закономерностей, ни о методах их оценки.
Рассмотрим еще один пример такого сложного мема, синтезированного из нескольких субмемов. «Полученные результаты обработаны методом вариационной статистики с применением t-критерия Стьюдента, x2 и метода ранжирования непараметрических данных (статья «Особенности терапии верапамилом, нитратами и корватоном у больных со стенокардией в сочетании с гипотонией», Сибирский медицинский журнал, №2, 1996 г., стр. 26.). Первая часть этого мема сообщает об использовании вариационной статистики. Хотя это название и является уже устаревшим (см. например, книгу П.Ф. Рокицкого «Биологическая статистика» (1973 г.), где он объясняет свой отказ от прежнего названия «Вариационная статистика»), однако само по себе оно не конфликтует с остальным содержанием мема и статьи. Однако упоминание о t-критерии Стьюдента уже требует выполнения двух обязательных условий, о чем ни в данном меме, ни в самом тексте статьи ничего не сообщается. Из чего можно сделать достаточно обоснованное предположение о том, что авторы не проверяли эти условия. Далее, обратимся к результатам проверки гипотез о равенстве средних в группах, приведенным в таблицах 1...3 на стр. 29. В табл. 1 речь идет о числе приступов стенокардии, т.е. о дискретной величине. Такая же дискретная величина и в табл.3 – число гипоперфузируемых сегментов. По причине дискретности этих величин, имеющих достаточно ограниченное число значений, применение t-критерия Стьюдента невозможно. И только в табл. 2 речь идет о непрерывной величине – продолжительности (времени) пороговой нагрузки, и поэтому в принципе, при выполнении известных ограничений, в данном случае применение t-критерия Стьюдента возможно. Однако остается вопрос, как же проверялись гипотезы в табл. 1 и 3? В анализируемом меме после t-критерия Стьюдента речь идет о критерии «Х-квадрат». Предполагая, что при наборе текста вместо греческой буквы «χ» была набрана латинская буква «Х», можно далее предположить, что здесь речь идет о критерии «χ2». Однако этот критерий не используется для проверки подобных гипотез. Неясно тогда и какие же гипотзе и в каких случаях проверялись с его помощью, поскольку в тексте статьи о них ничего не сообщается. Далее в тексте мема упоминается «метод ранжирований непараметрических данных». Что такое «непараметрические данные» видимо известно только кому-то из 8 соавторов этой статьи. Поскольку и в «вариационной статистике», как и в математической статистике, отсутствует такое понятие, как «непараметрические данные» [107, 108]. Итак, какими же статистическими критериями получены выводы в табл. 1 и 3 и что такое «непараметрические данные»?
Еще один пример мема не поддающегося анализу. «Для исследования соотношения определяемых факторов использовался многоуровневый корреляционный анализ» – стр. 21 диссертации «Состояние местного иммунитета при язвенной болезни», 14.00.05 – внутренние болезни, 1994 г. Ни контекст этого мема, ни содержание диссертации никак не расшифровывают, что подразумевал диссертант под «многоуровневым корреляционным анализом». Можно предположить, что корреляционный анализ выполнялся последовательно на разных уровнях (в разных иерархически расположенных группах) и затем коэффициенты корреляции для одних и тех же пар признаков разных уровней сравнивались между собой. Однако изложенные в диссертации результаты исследования не содержат ни таких уровней, ни сравнения разноуровневых коэффициентов корреляции.
Во многих работах само понятие «закономерности» для авторов ассоциировало с понятием функции и функциональной связи. В частности, нередко в тех местах своего описания, где автор вел речь об оценке зависимостей между различными изучаемыми показателями, наблюдались рекомбинации со словосочетаниями «функциональная зависимость» или «функциональная связь». «Функциональная зависимость между показателями определялась с помощью корреляционного и регрессионного анализа» – стр. 46 диссертации «Функции почек и водно-солевой баланс у крыс при гипо- и гиперосмии в динамике беременности», 14.00.17 – нормальная физиология, 1992 г. «Функциональная связь при коэффициенте корреляции ® до 0,5 оценивалась как слабая, 0,5 – 0,7 средняя, 0,7 – 0,9 сильная и от 0,9 до 1,0 как тесная» – стр. 50 диссертации «Особенности регуляторно-метаболических параметров иммунокомпетентных клеток крови у лиц с разным соматотипом», 14.00.17 – нормальная физиология, 1997 г. Элементарное представление о функции сейчас изучается в начальной школе. Обратимся к статье «Функция» в «Советском энциклопедическом словаре» (1982 г., стр. 1449): «Функция (матем.), 1) зависимая переменная величина. 2) Соответствие y = f(x) между переменными величинами, в силу которого каждому рассматриваемому значению некоторой величины х (аргумента, или независимого переменного) соответствует определенное значение другой величины y (зависимой переменной, или функции). Такое соответствие может быть задано различным образом, например, формулой, графически или таблицей (типа таблицы логарифмов).» Теперь обратимся к статье «Корреляция» на стр. 642 этого же словаря: «Корреляция (в матем. статистике), вероятностная или статистическая зависимость. В отличие от функциональной зависимости корреляция возникает тогда, когда зависимость одного из признаков от другого осложняется наличием ряда случайных факторов». Аналогичным же образом определяется этот термин и в «Статистическом словаре» (1989 г., стр. 213): «Корреляция – зависимость между случайными величинами, не имеющая строго функционального характера, при которой изменение одной из случайных величин приводит к изменению математического ожидания другой».
Итак, функциональная зависимость и корреляционная или регрессионная зависимости являются антиподами. В живых организмах, как наиболее сложных природных творениях, практически не встречаются функциональные зависимости в чистом виде, а преобладают именно вероятностные, статистические. И именно по этой причине столь необходима прикладная статистика как инструмент исследования в биомедицине.
Наиболее частая конструкция рекомбинированного мема описания состоит из двух или трех ядер. В одном из них, обычно в первом ядре, упоминается сам факт использования ЭВМ или персонального компьютера. В следующем ядре упоминается название одного или нескольких статистических методов. И завершает эту конструкцию упоминание названия статистического пакета. Как правило, при использовании подобных рекомбинированных мемов далее в тексте авторы уже не возвращаются к их содержимому. Например, выше мы уже упоминали статью «Использование эссенциальных фосфолипидов в лечении больных ишемической болезнью сердца и инсулиннезависимым сахарным диабетом» (Кардиология, 1996, №1, стр. 30...33), где все описание имеет следующий вид (стр. 31): «Полученные данные обрабатывали на ЭВМ методами многомерной статистики». Однако отсутствие в тексте статьи даже намеков на эти самые «многомерные методы» и обсуждения результатов их применения, позволяют высказать вполне обоснованное предположение о том, что данное описание является не более чем камуфляжным мемом. Наличие таких мемов в статьях журнала «Кардиология» не является какой-то редкостью, несмотря на требования самой редакции журнала о детальном описании авторами статей использованных ими статистических методов.
Локализация мемов внутри научных школ
Описания, приведенные в следующих 2 кандидатских и 3 докторских диссертациях представляют особый интерес. Четыре из них относятся к одной и той же научной специальности 14.00.17 – нормальная физиология, а 5-я диссертация защищена по близкой специальности 14.00.16 – пат. физиология. Интересно и то, что, один и тот же человек выступает в роли научного руководителя в кандидатских диссертациях и в роли научного консультанта в докторских диссертациях. Автор же докторской диссертации №8 выступает в качестве научного руководителя в кандидатской диссертации №7. Все это позволяет говорить о принадлежности диссертантов к одной научной школе. Более того, как видно из приведенных ниже наименований этих работ, они достаточно близки и по следующим элементам:
- срокам выполнения работ: – 1992 г., 1993 г., 1994 г. и 1995г;
- объектам исследования;
- структуре названия работ – в трех диссертациях одно и то же первое слово, а в двух диссертациях полностью совпадают первые четыре слова.
Ниже приведены названия данных работ, научная специальность и год защиты этих диссертаций.
Диссертация №7 – Роль поджелудочной железы в регуляции антитрипсиновой и трипсиновой активности крови. Канд. диссер., 14.00.17 – нормальная физиология. 1992 г.
Диссертация №8 – Роль трипсина в регуляции моторной функции тонкой кишки. Докт. дисс., 14.00.17 – нормальная физиология. 1992 г.
Диссертация №9 – Роль поджелудочной железы в регуляции состояния калликреин-кининовой системы крови. Канд. диссер., 14.00.17 – нормальная физиология. 1993 г.
Диссертация №10 – Функционирование калликреин-кининовой системы крови в норме и при патологии. Докт.. дисс., 14.00.16 – пат. физиология. 1995 г.
Диссертация №11 – Механизмы образования и деградации надэпителиального слизистого слоя пищеварительного тракта. Докт. диссер., 14.00.17 – нормальная физиология. 1994 г.
Таблица 4.
| Описание из диссертации №7 [стр. 35] | Описание из диссертации №8 [стр. 49] | Описание из диссертации №9 [стр. 39] | Описание из диссертации №10 [стр. 59] | Описание из диссертации №11 [стр. 68] |
| Достоверными считались отличия с уровнем доверительной вероятности p < 0,05 | Достоверными считались отличия с уровнем доверительной вероятности p < 0,05 | Достоверными считались отличия с уровнем доверительной вероятности p < 0,05 | Достоверными считались отличия с уровнем доверительной вероятности p < 0,05 | Достоверными считали различия с уровнем доверительной вероятности p < 0,05 |
Все это позволяет сделать вывод о том, что в этой научной школе прочно закрепился и культивируется данный мем ошибочного понимания и описания самого смысла доверительной вероятности. Для того, чтобы это утверждение было осознано и понято читателями даже далекими от прикладной статистики, приведем цитаты касающиеся понятия доверительной вероятности из нескольких популярных книг по статистике (с указанием страницы, на которой расположена цитата), и далее сравним их с анализируемым мемом. Жирным шрифтом и цветом выделим ту часть цитат, которая будет наиболее важна для нашего последующего анализа.
«Доверительная вероятность – вероятность того, что оцениваемый вектор характеристики (параметров) совокупности генеральной накрывается доверительной областью (доверительным интервалом – оценкой интервальной при одном параметре). Доверительная вероятность должна быть достаточно большой, т.е. отвечать принципу практической достоверности. Другие названия: надежность доверительной области, доверительный коэффициент.» – Статистический словарь. М.: Финансы и статистика, – 1989, стр. 117...118.
«А теперь рассмотрим интервальные оценки, т.е. возможность, исходя из выборочных значений x1, x2,...xn, построения некоторого интервала, содержащего истинное значение параметра Q с заданной вероятностью. Метод получения таких интервалов сводится к построению нижнего и верхнего доверительных пределов Qн и Qв (Qн и Qв есть функции от выборочных значений), и если мы говорим, что истинное значение параметра лежит между этими доверительными пределами, то это утверждение выполняется с вероятностью (1 – e) и не выполняется с вероятностью e (число (1 – e) называется доверительным уровнем), Следовательно, выбрав достаточно малое число (обычно в биологических задачах 0,05 или 0,01), мы по выборочным значениям x1, x2,...xn, построим доверительный интервал (Qн, Qв), соответствующий доверительному уровню 1 – e. Обычно строят так называемые центральные доверительные интервалы. Очень часто, когда доверительный уровень измеряется в процентах, применяется термин 100(1 – e)%-ный интервал (например, 95%-ный доверительный интервал confidence interval, если 1 – e = 0,95).» – Компьютерная биометрика / Под ред. В.Н. Носова. – М.: Изд-во МГУ, 1990, стр. 44.
«Значительно более глубокое утверждение, чем в случае точечной оценки, можно сделать, оценивая доверительный интервал. Доверительный интервал вычисляется по данным из некоторой выборки; фиксированная величина параметра ансамбля заключена между границами этого интервала, называемыми доверительными пределами, с некоторой заданной степенью достоверности, называемой доверительной вероятностью.» – Д. Химмельблау. Анализ процессов статистическими методами. М.: Мир, 1973, стр. 124.
«Доверительный коэффициент – вероятность того, что случайно выбранный интервал из совокупности всех возможных доверительных интервалов, будет содержать искомый параметр. В примере доверительный коэффициент был равен 0,90. Иначе говоря: «Был построен доверительный интервал с доверительным коэффициентом 0,90». В конце концов мы говорим о построении доверительного интервала в окрестности выборочной статистики и для параметра, поскольку в данной совокупности параметр принимает только одно значение. Например,
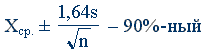
доверительный интервал для М в окрестности Xср.» – Дж. Гласс, Дж. Стэнли. Статистические методы в педагогике и психологии. М.: Прогресс, 1976, стр. 236.
«В этом параграфе мы рассмотрим вопрос получения интервальных оценок, т.е. возможность построения некоторого интервала, содержащего истинное значение параметра с заданной точностью. Сам метод получения таких интервалов сводится к построению так называемых доверительных пределов, а полученные интервалы называются доверительными. Процедура, которую мы собираемся описать в этом параграфе, состоит в построении нижнего и верхнего доверительных пределов уровня (1 – а), обладающих следующим свойством: если мы говорим, что истинное значение параметра лежит между этими пределами, то это утверждение верно с вероятностью 1 – а (и неверно с вероятностью а). Очевидно, что а следует выбирать достаточно малым (обычно используемые значения равны 0,05 и 0,01). Число 1 – а называют коэффициентом доверия или доверительной вероятностью». – К.А. Браунли. Статистическая теория и методология в науке и технике. М.: Наука, 1977, стр. 114.
Закончим этот экскурс в описание понятия доверительной вероятности, часто цитируемым в биомедицинских публикациях учебным пособием Г.Ф. Лакина «Биометрия», М.: Высшая школа, 1990, стр. 106. «Вероятности, признанные достаточными для уверенного суждения о генеральных параметрах на основании известных выборочных показателей, называют доверительными вероятностями. Понятие о доверительных вероятностях предложено Р. Фишером. Оно вытекает из принципа, который положен в основу применения теории вероятностей к решению практических задач. Согласно этому принципу, маловероятные события считают практически невозможными, а события, вероятность которых близка к единице, принимают за почти достоверные. Обычно в качестве доверительных используют вероятности Р1 = 0,95; Р2 = 0,99; Р3 = 0,999.»
Итак, основной акцент, который делается во всех этих цитатах, заключается в том, что величина доверительной вероятности, т.е. степени нашей уверенности в декларируемых утверждениях, должна быть достаточно близка к 1. В противном же случае, если эта величина близка к нулю, теряется ее смысл как степени уверенности, доверия к этим утверждениям. Таким образом, 5 авторов использовавших приведенный выше мем, утверждали, что степень их уверенности в своих выводах не более 5%! Наличие подобного растиражированного мема означает и то, что это утверждение не смутило никого из руководителей и консультантов этих диссертаций, ни представителей ведущих организаций, ни оппонентов, ни экспертов ВАК РФ. Таким образом, «экологическая ниша», где циркулирует данный мем, гораздо шире! Напомним, что эти утверждения приведены не в дипломных работах выпускников вуза, а в квалификационных работах на ученые степени кандидатов и докторов медицинских и биологических наук, авторы которых уже имели не одну печатную публикацию, а некоторые из них уже не первый год читают лекции студентам. Поэтому сомнительно, что приведенные мемы есть результат неточного изложения авторами своих мыслей. Скорее наоборот, что данные мемы и есть адекватное отображение устоявшегося у авторов искаженного представления о доверительной вероятности.
Анализ многих публикаций, авторы которых принадлежат одной научной школе или связаны каким либо иным образом, обнаружил присутствие в таких группах некоторого пула мемов, относящихся либо к наиболее популярным в этих группах статистическим методам, либо к их описанию. Нередко в диссертациях таких авторов обнаруживается практически дословное совпадение используемых мемов. Ниже приведено описание использованных в работе статистических методов, включающие следующие последовательно друг за другом три предложения из кандидатской диссертации №12 «Гормонально-иммунологические параллели у детей с аллергическим поражением кожи и органов дыхания», 14.00.09 – педиатрия, 1994 г.
Таблица 5.
| Описание из диссертации №12, [стр. 31] |
| Статистическая обработка полученных результатов проводилась на основе банка данных, доступ к которому реализован через пакеты программ «Ребус» и «Statgrafiks». |
| В тех случаях, когда распределение выборочной совокупности исследуемых показателей было близким к нормальному (выполнялось неравенство П.Л. Чебышова) проверка значимости различий средних осуществлялась по критерию Стьюдента или квантилю t нормального распределения. |
| Достоверность уравнений регрессии оценивалась по критерию Фишера (F). |
В качестве ядра первого мема можно выделить словосочетание «на основе банка данных, доступ к которому реализован через пакеты программ», которое мы встречали потом несколько раз в других, более поздних диссертациях. Ядро второго мема «неравенство П.Л. Чебышева» также встречалось в других публикациях. Отметим, что в одной из них, датированной 1995 г., полностью воспроизводились все три предложения, включая и ошибочное написание популярного статистического пакета: Statgrafiks вместо Statgraphics. Далее на стр. 31 этой же диссертации читаем: «Для определения информативности маркеров использован факторный анализ [46]. Клинико-иммунологическая классификация больных в трехмерном пространстве признаков проведена методом кластерного анализа [1,4].» Однако ни в тексте диссертации, ни в таблицах, ни в обсуждении результатов и ни в «Заключении» не обнаруживаются никакие явные или косвенные признаки применения факторного и кластерного анализов.
В том эшелоне публикаций, который был нами проанализирован, можно достаточно надежно утвердать, что в каждой научной школе циркулирует свой, характерный именно ей пул мемов. Нередко подобный пул мемов переходит из одной публикации в другую вместе с тем соавтором, который по мнению авторского коллектива является наиболее подготовленным в этой области. Эта достаточно устойчивая популяция меметических описаний определяется несколькими причинами. Можно выделить два наиболее важных фактора формирования этого пула мемов. Во-первых, это эталоны в виде статейных публикаций и диссертаций научных руководителей этих школ и подразделений. Именно они своим уровнем требований к собственным работам и работам своих учеников задают рабочий вектор используемых методов анализа экспериментальных данных. Мы неоднократно наблюдали положительную корреляцию между качеством анализа данных в диссертации научного руководителя или консультанта, и качеством анализа данных в руководимой или консультируемой им кандидатской диссертации. В качестве примера такой связи можно назвать две диссертации, которые могут служить хорошим эталоном использования современных методов прикладной статистики в биомедицинских исследованиях. Первая работа, это докторская диссертация Канской Н.В. по теме «Роль взаимосвязи дислипопроидемий и иммунологических нарушений в патогенезе коронарного атеросклероза», 14.00.16 – пат. физиология, 15.00.04 – биохимия, НИИ кардиологии ТНЦ РАМН, Томск, 1990 г. В данной работе использовано порядка десятка разнообразных статистических методов, и в том числе такие как дискриминантный и кластерный анализ. Следующая работа, где доктор мед. наук Канская Н.В. была научным консультантом, – кандидатская диссертация Горленко Л.В. по теме «Влияние патологии гепатобилиарной системы на возникновение и развитие атерогенных нарушений у детей», 14.00.09 – педиатрия, 14.00.04 – биохимия, НИИ Кардиологии ТНЦ РАМН, Томск, 1996 г. В данной диссертации, как и в предыдущей, также использован достаточно широкий спектр статистических методов и критериев, включая критерии Вилкоксона и Крускала-Уоллиса и такие многомерные методы статистики, как факторный и кластерный анализ. Отметим, что в данных работах использованные методы и критерии гармонично входят в ткань задач исследования и являются естественным и логичным продолжением грамотно сформулированных целей исследования. Немаловажным фактором формирования этого пула являются и статьи по данному научному направлению, публикуемые в профильных периодических журналах и трудах конференций.
Анализ разнообразных мемов, близких по своим конструкциям, подтверждает идеи высказанные В.В. Налимовым в своих работах [109, 110] о вероятностном распределении смыслов. Действительно, семантика анализируемых мемов определяется вероятностным распределением смыслов отдельных составных частей мема. Причем, одни и те же элементы мемов не обязательно имеют унимодальное (одновершинное) распределение плотности вероятности. Наиболее типичный пример такого тримодального распределения – это восприятие величины «p <» следующим образом:
- как уровня значимости;
- как доверительной вероятности;
- как абсолютной точности.
|
Дата публикации: 15 августа 1999 года |
|